
Important links
Abstract
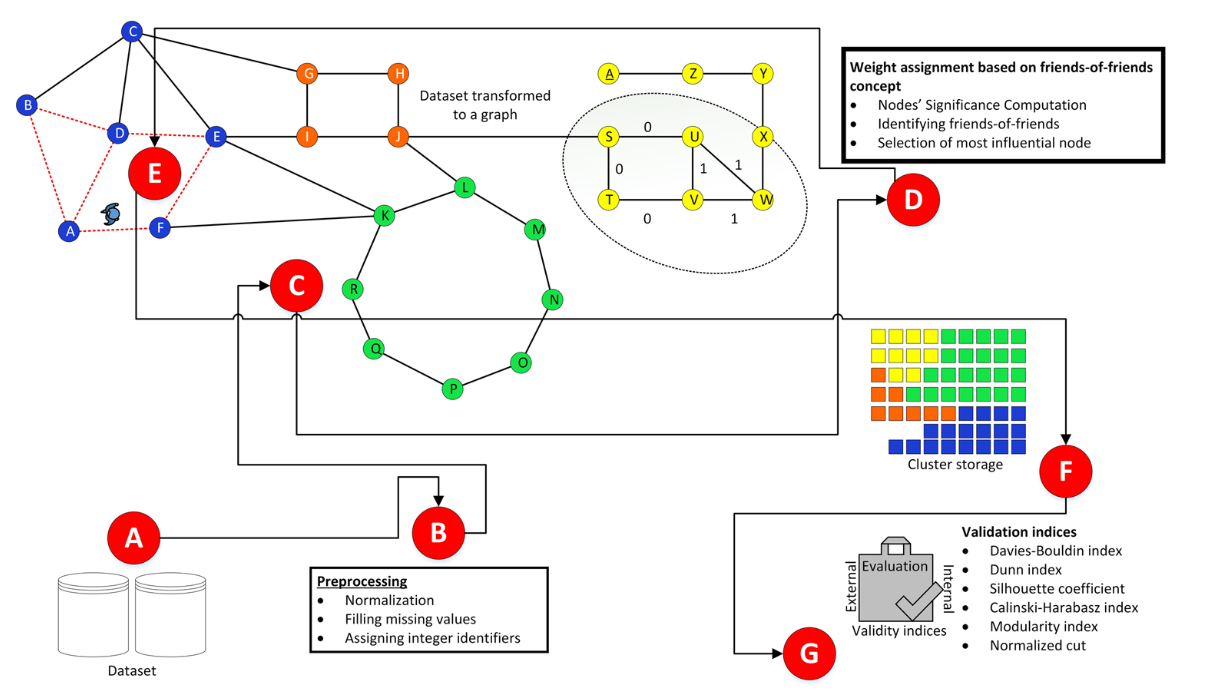
Clustering is an unsupervised learning task that models data as coherent groups. Multiple approaches have been proposed in the past to cluster large volumes of data. Graphs provide a logical mapping of many real-world datasets rich enough to reflect various peculiarities of numerous domains. Apart from k-means, k-medoid, and other well-known clustering algorithms, utilization of random walk-based approaches to cluster data is a prominent area of data mining research. Markov clustering algorithm and limited random walk-based clustering are the prominent techniques that utilize the concept of random walk. The main goal of this work is to address the task of clustering graphs using an efficient random walk-based method. A novel walk approach in a graph is presented here that determines the weight of the edges and the degree of the nodes. This information is utilized by the pseudo-guidance model to guide the random walk procedure. This work introduces the friends-of-friends concept during the random walk process so that the edges’ weights are determined utilizing an inclusive criterion. This concept enables a random walk to be initiated from the highest degree node. The random walk continues until the walking agent cannot find any unvisited neighbor(s). The agent walks to its neighbors if it finds a weight of one or more, otherwise the agent’s stopping criteria is met. The nodes visited in this walk form a cluster. Once a walk comes to halt, the visited nodes are removed from the original graph and the next walk starts in the remaining graph. This process continues until all nodes of the graph are traversed. The focus of this work remains random walk-based clustering of graphs. The proposed approach is evaluated using 18 real-world benchmark datasets utilizing six cluster validity indices, namely Davies-Bouldin index (DBI), Dunn index (DI), Silhouette coefficient (SC), Calinski-Harabasz index (CHI), modularity index, and normalized cut. This proposal is compared with seven closely related approaches from the same domain, namely, limited random walk, pairwise clustering, personalized page rank clustering, GAKH (genetic algorithm krill herd) graph clustering, mixing time of random walks, density-based clustering of large probabilistic graphs, and Walktrap. Experiments suggest better performance of this work based on the evaluation metrics.
Important figures
Citation
@article{halimClusteringGraphsUsing2021,
title = {Clustering of Graphs Using Pseudo-Guided Random Walk},
author = {Halim, Zahid and Sargana, Hussain Mahmood and {Aadam} and {Uzma} and Waqas, Muhammad},
year = {2021},
journaltitle = {Journal of Computational Science},
volume = {51},
pages = {101281},
issn = {18777503},
doi = {10.1016/j.jocs.2020.101281},
url = {https://www.sciencedirect.com/science/article/pii/S1877750320305779}
}